Cruising through complex data
This post is a showcase of data wrangling techniques in Python, using glom. If you haven't heard of glom, it's a data transformation library and CLI designed for Python. Think HTML templating, but for objects, dicts, and other data structures.

It's been almost five years since the first release of glom. That version now looks quaint in comparison to the just-released glom 23. Out of all the new functionality, we're going to take a look at six techniques that'll level up your complex data handling.
NB: Throughout the post, you'll note examples linking to a site called glompad. Like so many regex and JS playgrounds, glompad is glom in the browser. Very much an alpha, I'll save the details for another post. In the meantime, try it out and let me know how it goes!
Star path selectors
Years in the making, glom's newest feature is one of the longest anticipated. Since its first release, glom's deep get has excelled at fetching single values:
target = {'a': {'b': {'c': 'd'}}}
glom(target, 'a.b.c')
# 'd'
As of the latest release, glom now does glob-style * and ** as path segments,
aka wildcard expansion:
glom({'a': [{'k': 'v1'}, {'k': 'v2'}]}, 'a.*.k') # * is single-level
# ['v1', 'v2']
glom({'a': [{'k': 'v3'}, {'k': 'v4'}]}, '**.k') # ** is recursive
# ['v3', 'v4']
Notably, this is one of the only breaking features in glom's history. Star selectors were added as an option in glom 22, and baked for a year (with warnings for any users with stars in their paths) before becoming the default in glom 23.
Deep assignment and deletion
By default, glom makes and returns new data structures. But glom's default immutable approach isn't always a perfect fit for the messy, deeply-nested structures one gets from scraped DOMs, ancient XML, or idiosyncratic API wrappers.
So one of glom's earliest additions, way back in 2018,
enabled declarative deep assignments that would work across virtually all mutable Python objects.
First with Assign() and the assign() convenience function (example, docs):
target = {'a': [{'b': 'c'}, {'d': None}]}
assign(target, 'a.1.d', 'e') # let's give 'd' a value of 'e'
# {'a': [{'b': 'c'}, {'d': 'e'}]}
Assign also unlocked a super useful pattern of
automatically creating nested objects without the need for defaultdict and friends (example):
target = {}
assign(target, 'a.b.c', 'hi', missing=dict)
# {'a': {'b': {'c': 'hi'}}}
And for something more destructive, there's Delete() and delete() (example, docs):
target = {'a': [{'b': 'c'}, {'d': None}]}
delete(target, 'a.0.b')
# {'a': [{}, {'d': None}]}
Assign() and Delete() both shine when manipulating ElementTree-style documents from etree, lxml, html5lib, and the like.
Like glom's other path-based functionality, the nuances of assigning Python dict keys, object attributes, and sequence indices are handled for you.
There's also an extension system for adding support especially unique types.
The Data Trace
The main appeal of glom has always been succinct and robust data access and transformation. No single glom feature showcases this quite as much as the data trace.
Data traces make glom's errors far more debuggable than Python's default exceptions. You don't see internal glom or Python stack frames; just you, your code, and your data:
>>> target = {'planets': [{'name': 'earth', 'moons': 1}]}
>>> spec = ('planets', ['rings']) # a spec we expect to fail
>>> glom(target, spec)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/mahmoud/projects/glom/glom/core.py", line 1787, in glom
raise err
glom.core.PathAccessError: error raised while processing, details below.
Target-spec trace (most recent last):
- Target: {'planets': [{'name': 'earth', 'moons': 1}]}
- Spec: ('planets', ['rings'])
- Spec: 'planets'
- Target: [{'name': 'earth', 'moons': 1}]
- Spec: ['rings']
- Target: {'name': 'earth', 'moons': 1}
- Spec: 'rings'
glom.core.PathAccessError: could not access 'rings', part 0 of Path('rings'), got error: KeyError('rings')
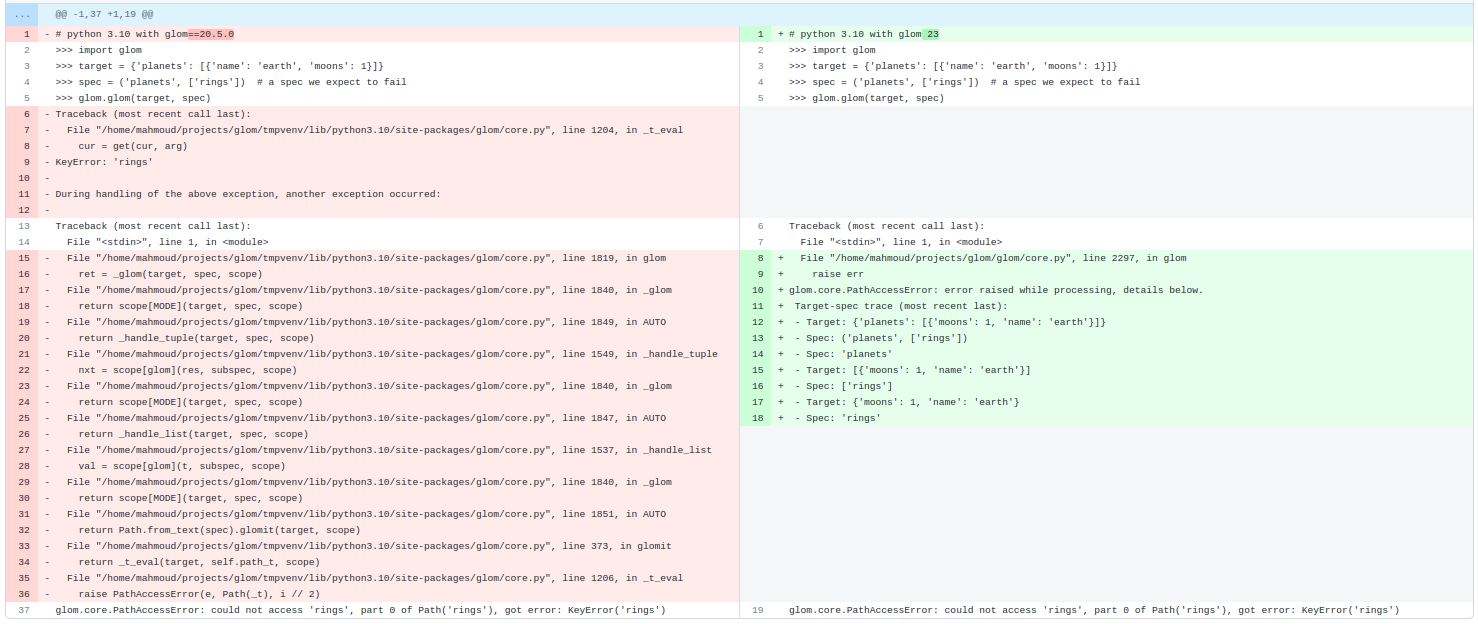
One day I'll write a post about how tracebacks are an oft-neglected part of a library's interface. The right traceback can turn an all-night debugging session into a quick fix anyone can push.
For now, see the doc with examples and more explanation here.
Pattern matching
While glom started as a data transformer, you often need to validate data before transforming it.
Data validation fits nicely into spec format, and so glom's Match specifier was born:
# load some data
target = [{'id': 1, 'email': 'alice@example.com'},
{'id': 2, 'email': 'bob@example.com'}]
# let's validate that the data has the types we expect
spec = Match([{'id': int, 'email': str}])
result = glom(target, spec)
# result here is equal to the data itself
Glom's pattern matching now features its own shorthand M spec, which is great for quick guards,
and a Regex helper, too:
# using the example data above, we can also validate the contents of the data
spec = Match([{'id': And(M > 0, int), 'email': Regex('[^@]+@[^@]+')}])
result = glom(target, spec)
# result here is again equal to the target data
Even a simple pattern matching example shows the power of the glom data trace. Check out the error message when some bad data gets added:
>>> target.append({'id': '3', 'email': 'charlie@example.com'})
>>> result = glom(target, spec)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "../glom/core.py", line 2294, in glom
raise err
glom.matching.TypeMatchError: error raised while processing, details below.
Target-spec trace (most recent last):
- Target: [{'email': 'alice@example.com', 'id': 1}, {'email': 'bob@example.com', 'id': 2}, {'ema... (len=3)
- Spec: Match([{'email': str, 'id': int}])
- Spec: [{'email': str, 'id': int}]
- Target: {'email': 'charlie@example.com', 'id': '3'}
- Spec: {'email': str, 'id': int}
- Target: 'id'
- Spec: 'id'
- Target: '3'
- Spec: int
glom.matching.TypeMatchError: expected type int, not str
The data trace gets even sweeter when we introduce flow control with Switch. See the data trace in action in this example. Users of shape-based typecheckers like Flow will especially appreciate the specificity of glom's error messages in these validation cases.
Streaming
For datasets too large to fit in memory, glom grew an Iter() specifier in 2019 (example, docs).
Iter() offers a readable chaining API that lazily creates nesting generators.
target = [1, 2, None, None, 3, None, 3, None, 2, 4]
spec = Iter().filter().unique() # this gives a streaming generator when evaluated
glom(target, spec.all()) # .all() converts the generator to a list
# [1, 2, 3, 4]
Iter()'s built-in methods also include .split(), .flatten(), .chunked(), .slice(), .limit() among others.
In short, endless possibilities for endless data.
Flattening and Merging
So much data revolves around iterables that in 2019 glom introduced the ability to "reduce" those iterables to flatter values, with the introduction of Flatten (example, docs):
list_of_iterables = [{0}, [1, 2, 3], (4, 5)]
flatten(list_of_iterables)
# [0, 1, 2, 3, 4, 5]
Even a mix of iterables (iterators, lists, tuples) combines nicely.
With Flatten came the numeric Sum, not unlike the builtin:
glom(range(5), Sum())
# 15
And the generic Fold, useful for some rare cases:
target = [set([1, 2]), set([3]), set([2, 4])]
result = glom(target, Fold(T, init=frozenset, op=frozenset.union))
# frozenset([1, 2, 3, 4])
A later release brought flattening to mappings, via Merge (example, docs):
target = [{'a': 'alpha'}, {'b': 'B'}, {'a': 'A'}]
merge(target)
# {'a': 'A', 'b': 'B'}
Merge() is great for deduping documents with a simple last-value-wins strategy.
Other core updates
The features above, and myriad others from the changelog, required multiple evolutions of the glom core. Underneath glom's hood is a loop that interprets the spec against the target. A simple, early version is preserved here in the docs.
However, the inner workings of the core were not part of glom's API, which limited extensibility. A lot of progress has been made in opening up glom internals for those use cases we couldn't predict.
Scope
Most transformations only requires a target and spec. Most... but not all.
For cases that needed additional state, like aggregation and multi-target glomming,
we added the glom Scope (example, docs):
# Make a spec that uses the T singleton to call
# the target's count method using the search value in the scope (S)
count_spec = T.count(S.search)
scope = {'search': 'a'} # additional context we'll pass in
glom(['a', 'c', 'a', 'b'], count_spec, scope=scope)
# 2
Here, the scope is used to pass in a search parameter which will be used against the target (T).
Usage can get quite advanced, including specs that write to the scope (example):
target = {'data': {'val': 9}}
spec = (S(value=T['data']['val']),
{'result': S['value']})
glom(target, spec)
# {'result': 9}
Here we grab 'val', save it to the scope as 'value', then use it to build our new result.
Modes
As discussed in pattern matching above,
some applications outgrew glom's initial data transformation behavior.
To handle these diverging behaviors, glom introduced the concept of modes.
Glom specs stay succinct by using Python literals, and modes allow changing the interpretation of those objects.
Glom comes with two documented modes, the default Auto() and Match() (example), which can be interleaved as necessary:
spec = Auto([Match(int, default=SKIP)])
target = [1, 'a', 2, 'c', 'a', 'b']
glom(target, spec)
# [1, 2]
We're working on adding more. You can easily add your own, too.
Extensions
We strive to make glom as widely applicable as possible, but data takes too many forms to count. We solve this by making glom extensible in several ways:
- Registering new target types and new operations on the target
- Creating new Spec types
- Adding new modes
By understanding glom's scope and its internals, it becomes clear that most built-in glom functionality is implemented through these public interfaces. So while glom can feel magical at times, now you can extend glom without touching the core, and be a part of the magic, too. ☄️
Not bad for five years, and we haven't even scratched all the surfaces, yet. Hopefully the next showcase won't be quite so far out.